SWIPER: Minimizing Fault-Tolerant Quantum Program Latency via Speculative Window Decoding
ISCA 2025
University of Chicago
University of Chicago
University of Chicago
University of Michigan
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Michigan
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Michigan
University of Chicago
University of Chicago
Abstract
Real-time decoding is a key ingredient in future fault-tolerant quantum systems, yet many decoders are too slow to run in real time. Prior work has shown that parallel window decoding schemes can scalably meet throughput requirements in the presence of increasing decoding times, given enough classical resources. However, windowed decoding schemes require that some decoding tasks be delayed until others have completed, which can be problematic during time-sensitive operations such as T gate teleportation, leading to suboptimal program runtimes. To alleviate this, we introduce SWIPER, a speculative window decoding scheme. Taking inspiration from branch prediction in classical computer architecture, SWIPER utilizes a light-weight speculation step to predict data dependencies between adjacent decoding windows, allowing multiple layers of decoding tasks to be resolved simultaneously. Through a state-of-the-art compilation pipeline and a detailed open-source simulator, we find that SWIPER reduces application runtimes by 40% on average compared to prior parallel window decoders.
* indicates equal contribution
[.pdf] [publication] [arXiv] [code]Selected Figures
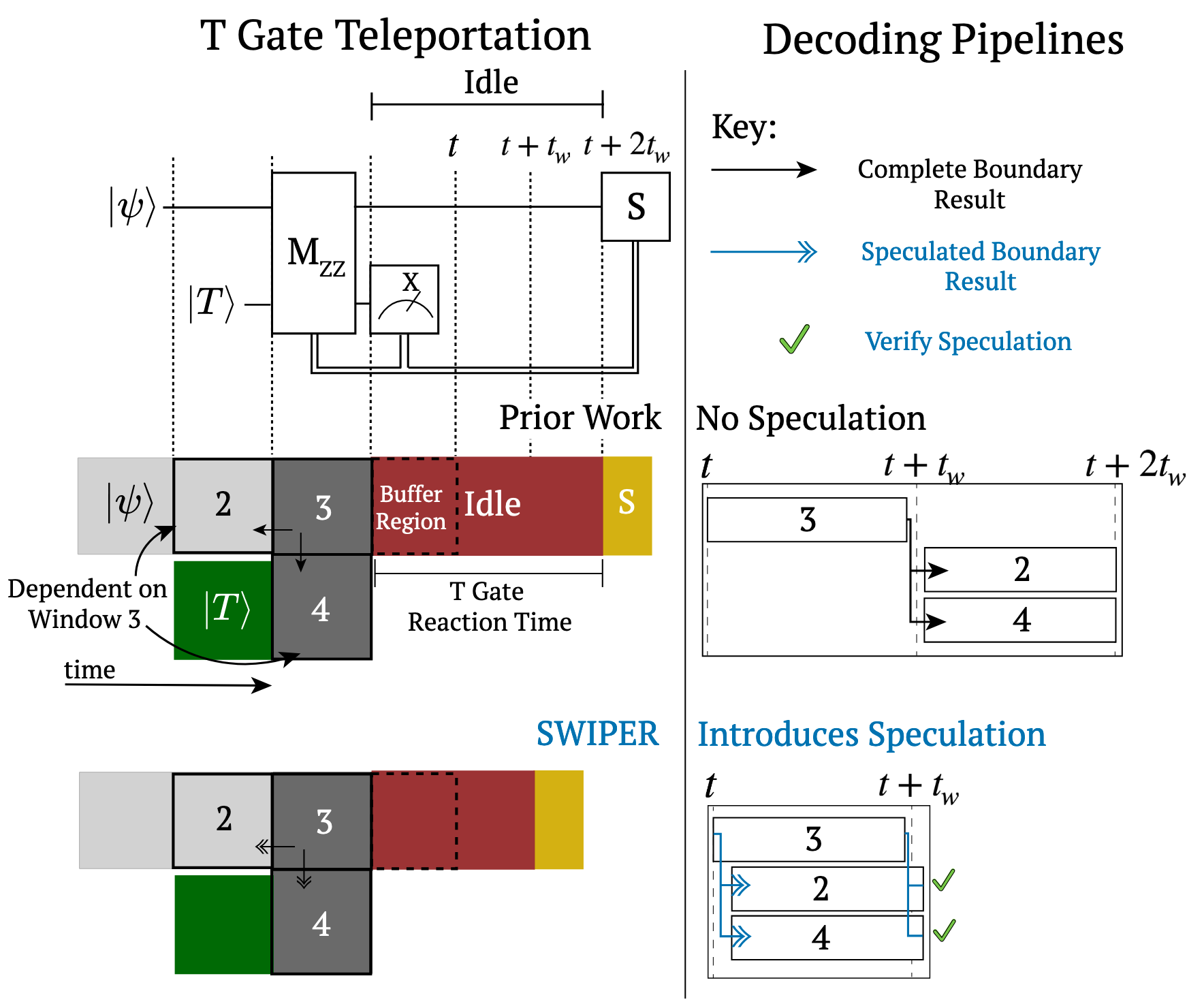
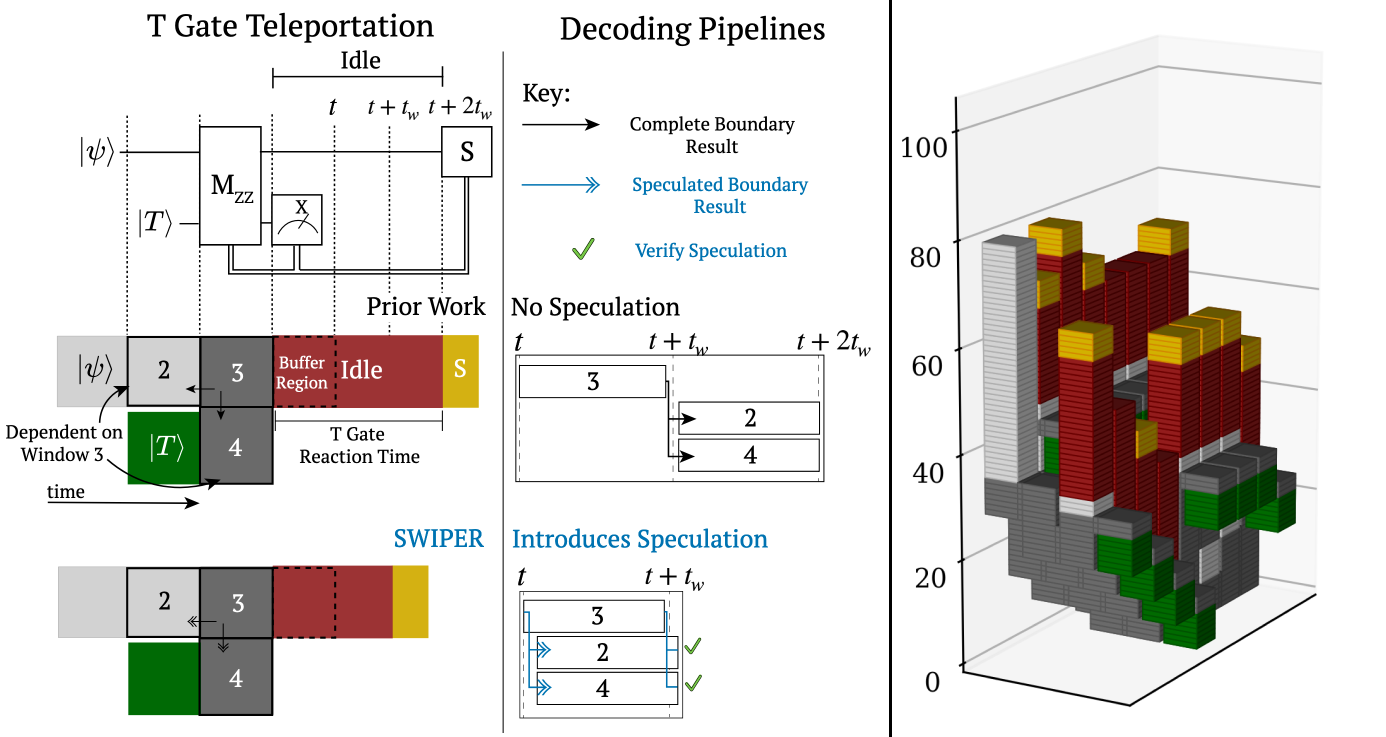
Figure 1. Decoding a lattice surgery T gate teleportation (top left) using prior parallel window decoders (middle) and using SWIPER (bottom). SWIPER improves decoding throughput with a lightweight speculation step, allowing dependent windows to begin decoding earlier
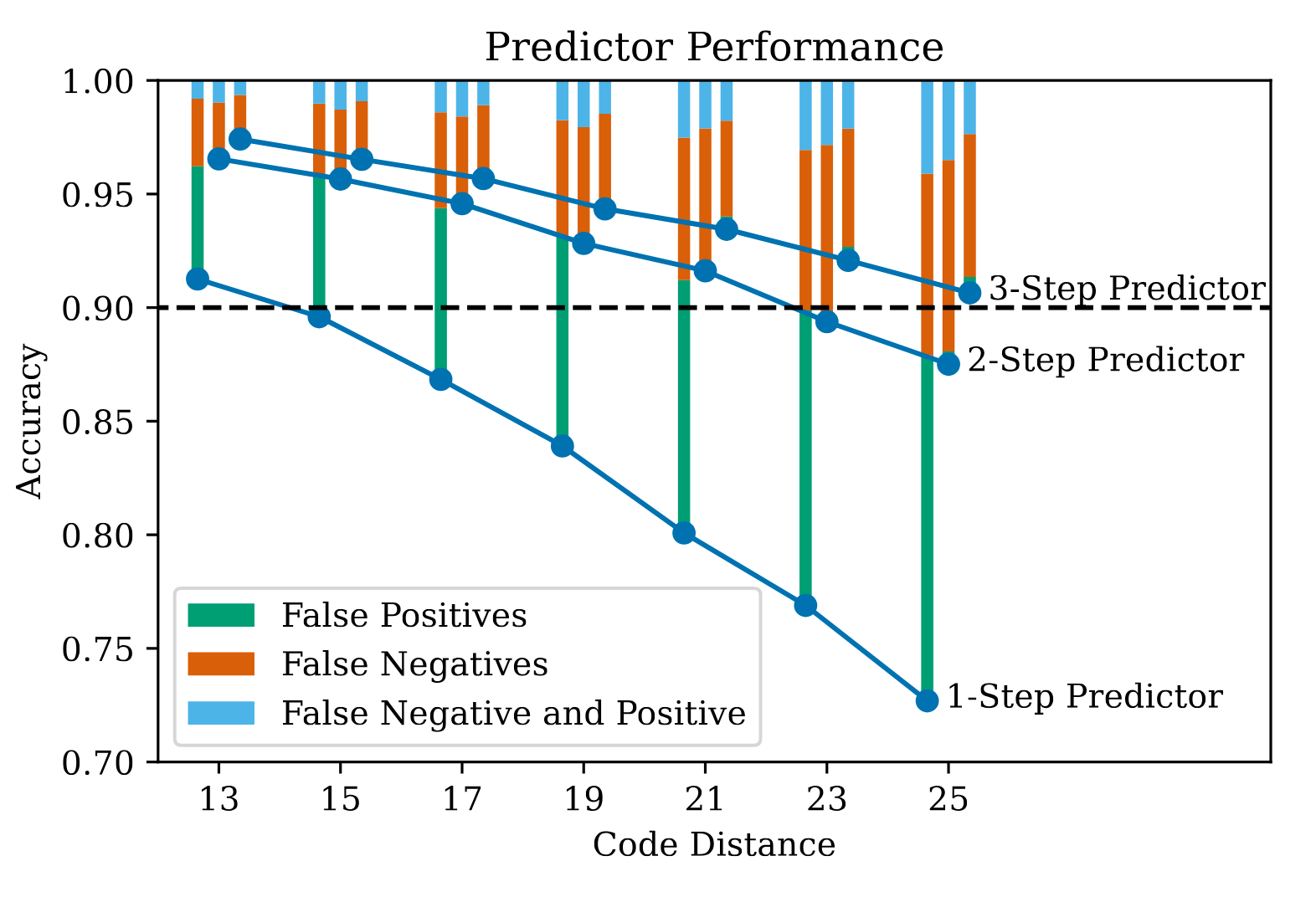
Figure 4. Accuracy of the three different predictors for increasing values of code distance. Bars indicate a breakdown of different failure cases.
Figure 6. An overview of the final, 3-step predictor logic.
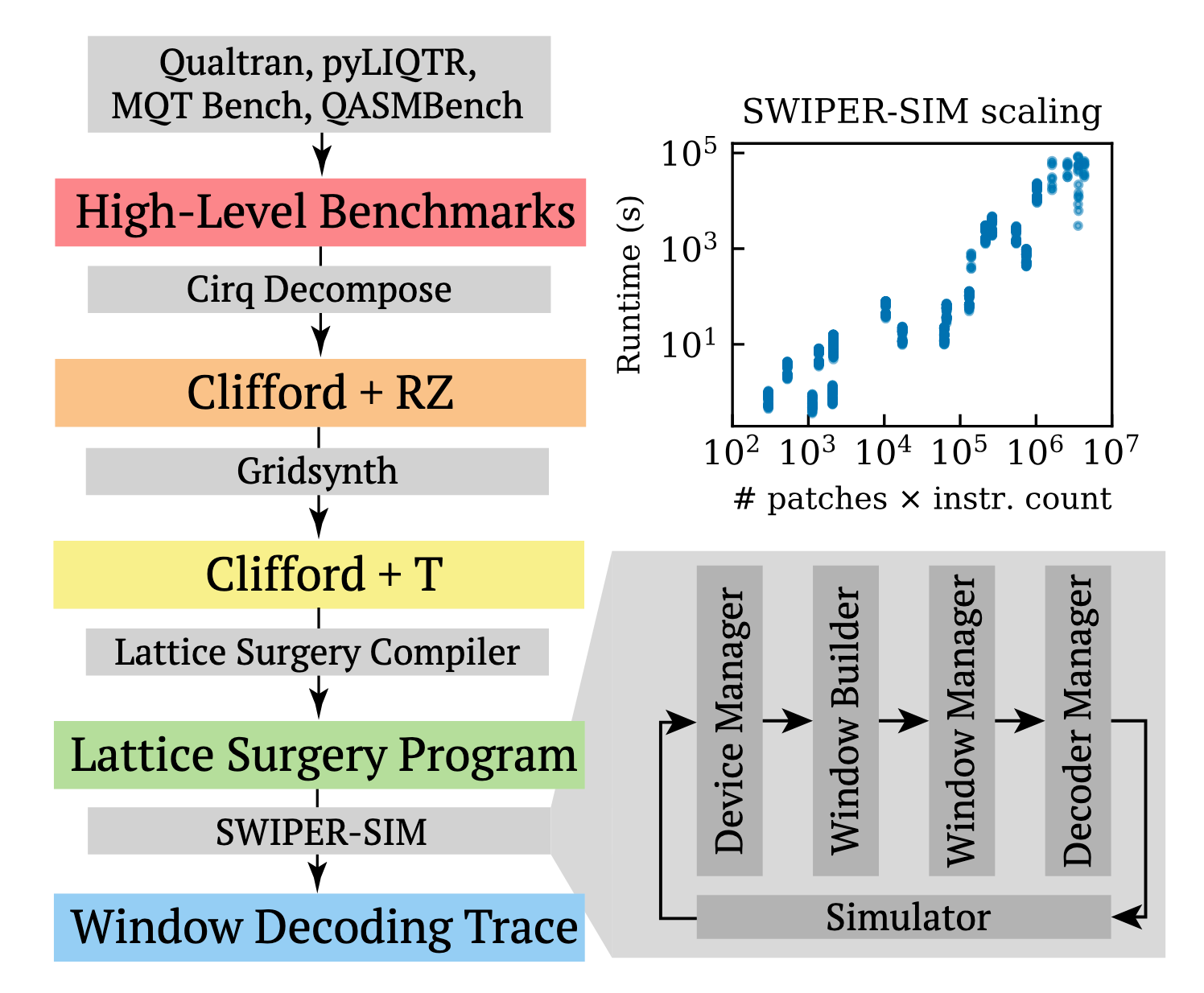
Figure 9. The pipeline used to evaluate high-level benchmark programs with different window decoders. Right: details of SWIPER-SIM and its performance scaling versus program size.
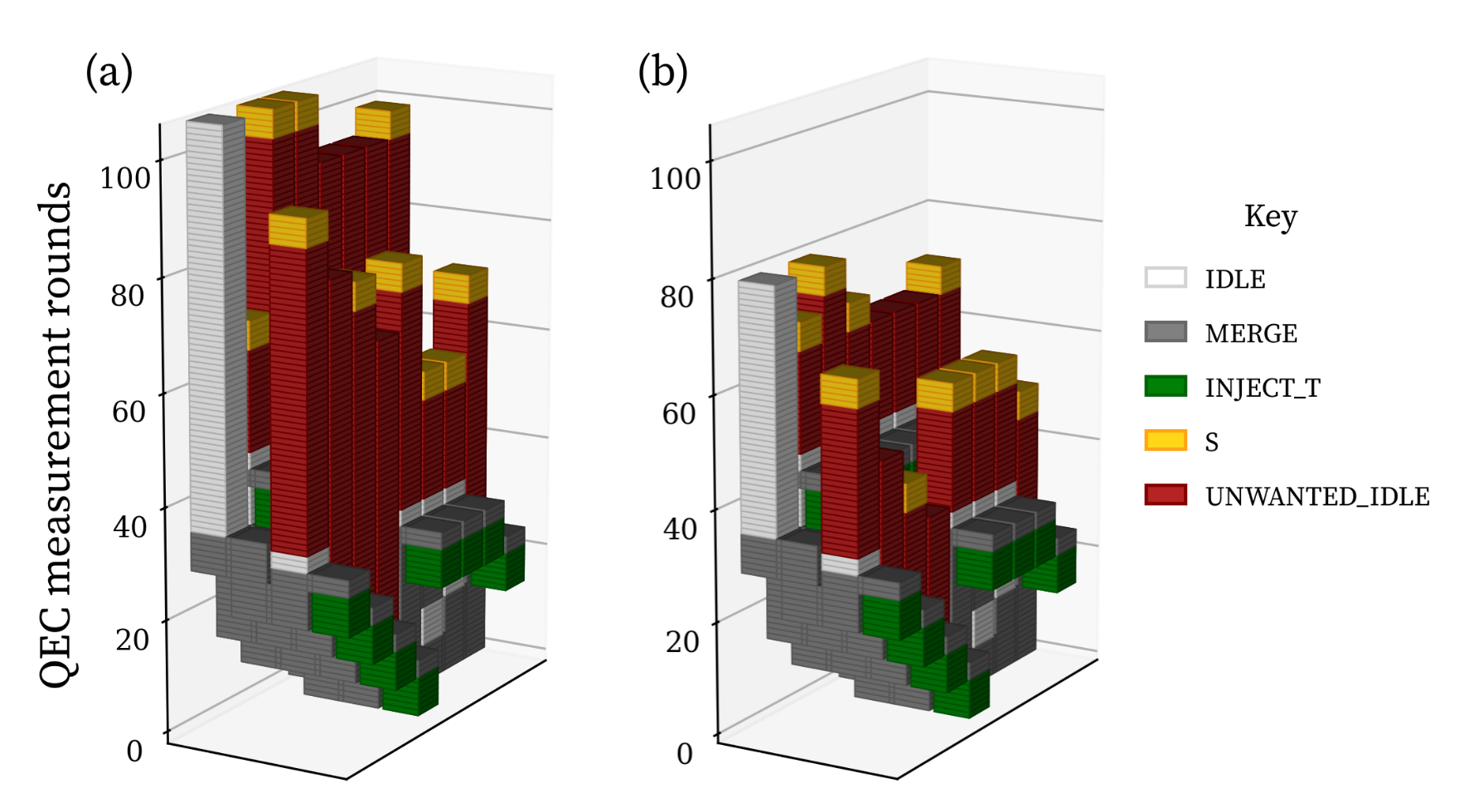
Figure 10. SWIPER-SIM program traces for a 15-to-1 magic state distillation in a distance-7 code using the construction from [24] (Fig. 17). Time advances vertically, and each horizontal slice represents a batch of syndrome data (colored by instruction type). Decoding time is fixed to be the same as the time to generate 2d rounds, about twice the window generation rate. Device traces are shown for (a) baseline parallel window method (15.1d QEC rounds) and (b) SWIPER aligned window (11.3d QEC rounds, a 25% improvement).
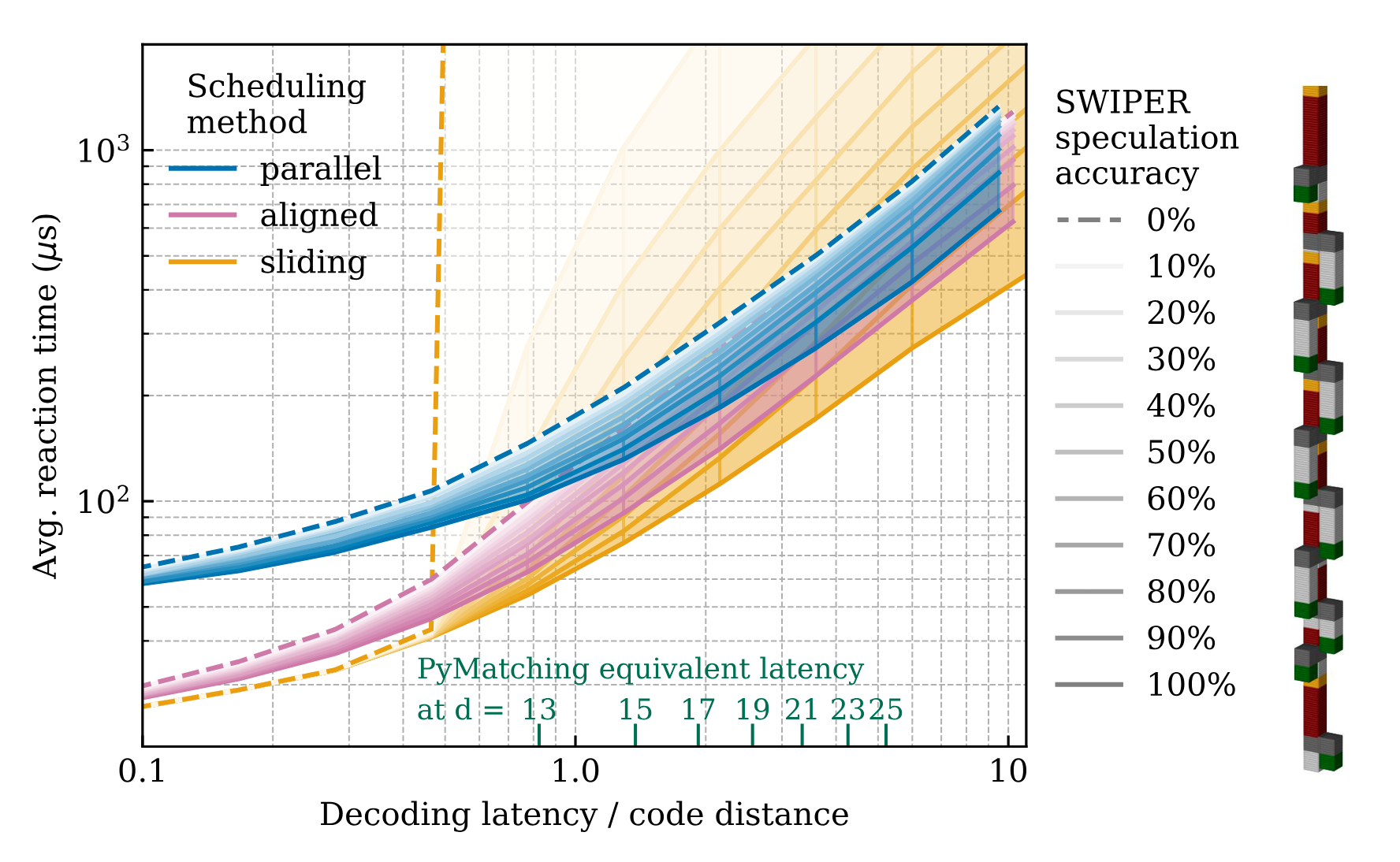
Figure 11. Sensitivity of reaction time to decoding latency and speculation accuracy. Speculation accuracy of 0% corresponds to baseline (no speculation) decoding. Decoder latency is $t_{\text{dec}}(v) = rv/d^2$ rounds, where $v$ is the volume of the decoding problem (in units of $d^3$) and the relative latency factor $r$ is varied along the x axis. Equivalent latency factors extracted from linear fits to PyMatching latency data (Figure 3) are shown along the x axis. Right: simulator trace of 10 T gates on an idling logical qubit. A similar experiment with 1000 T gates was used to collect the data in this figure.
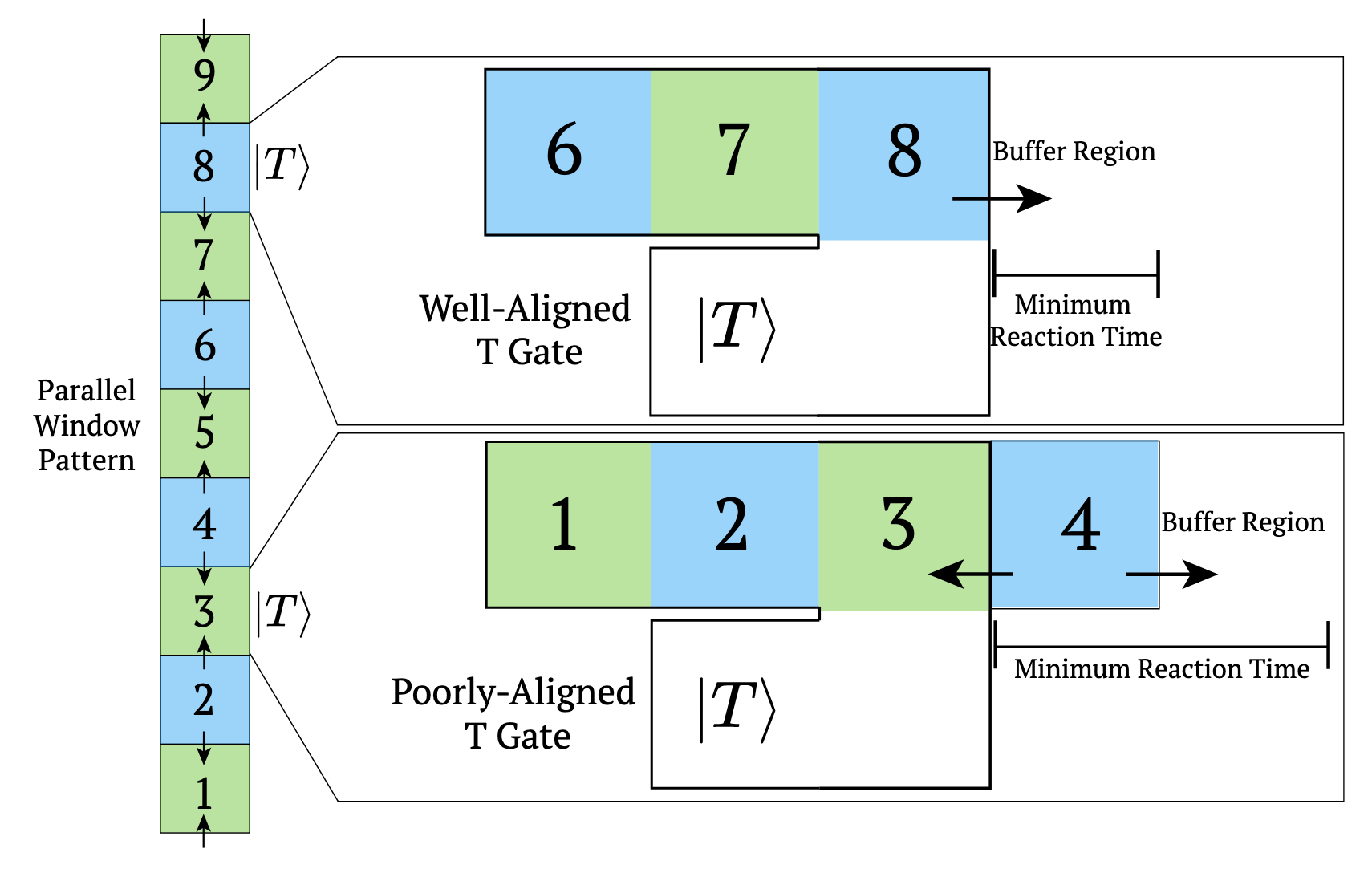
Figure 12. Comparing a well-aligned T gate (top) and a poorly- aligned T gate (bottom).
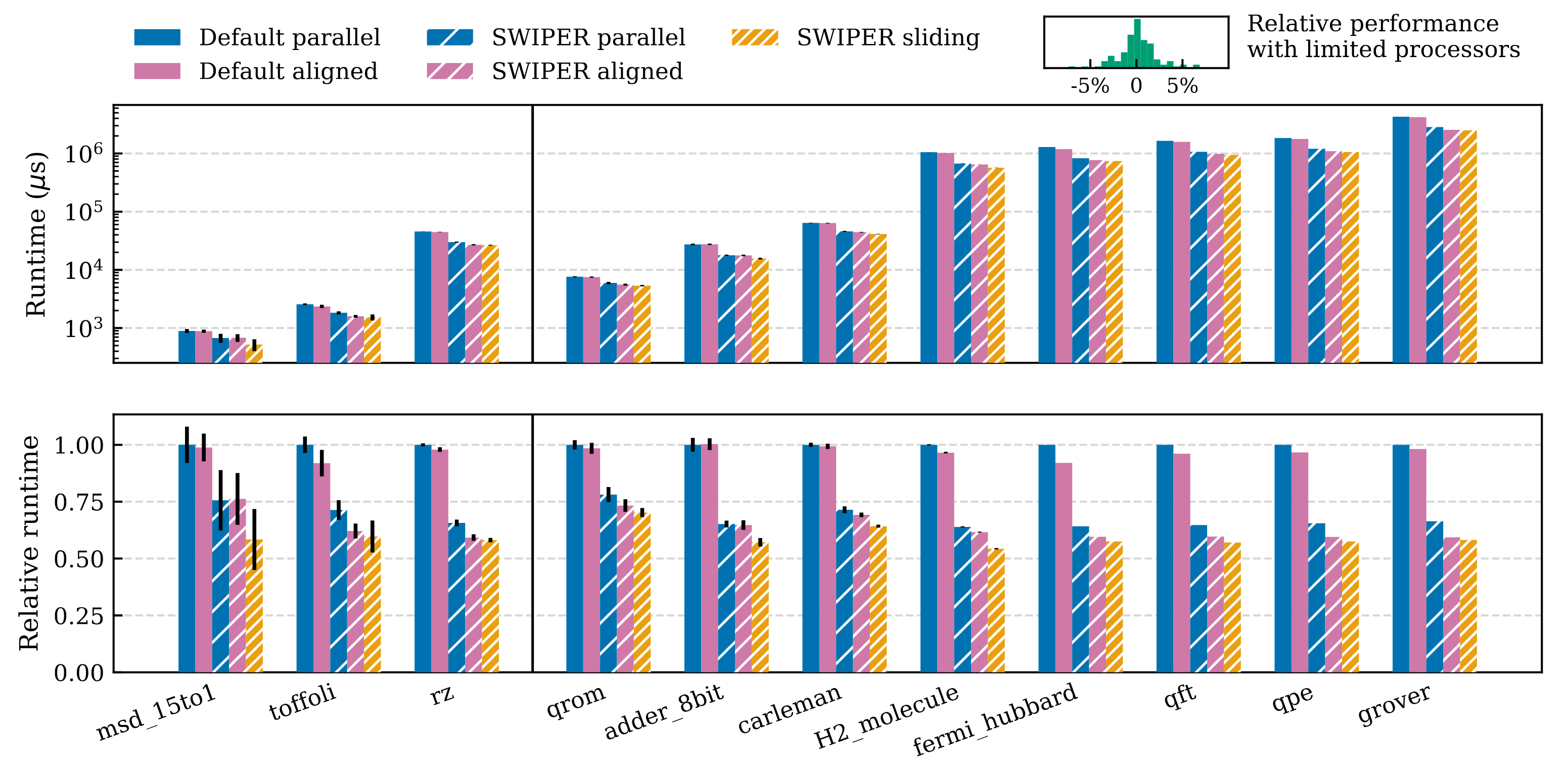
Figure 13. Top: Program runtime for selected benchmarks under different window scheduling methods, with and without SWIPER. Classical processor resources are unlimited. Vertical black lines indicate standard deviation over 10 randomized trials for smaller benchmarks. Top right: Relative differences in runtime when using auto-limited processor count (Section 5.3.4) for benchmarks with runtime longer than $10^4 \mu s$. Bottom: Relative runtimes normalized to default parallel window runtime.
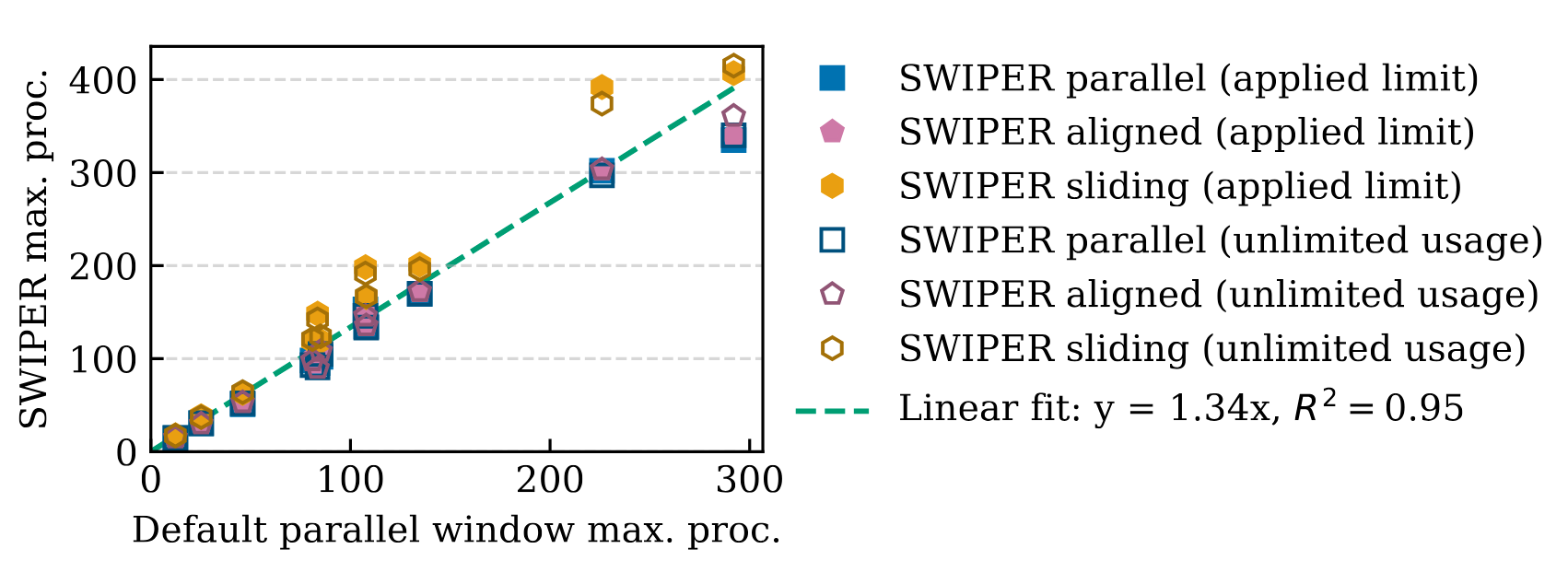
Figure 15. Comparing classical compute cost between baseline method and SWIPER.
My Contributions
← back to jason-chadwick.com